8.1 Lista
Listas são o segundo tipo de vetor. O primeiro tipo nós já vimos, são os vetores atômicos, nos quais todos os elementos devem ser dados do mesmo tipo. Listas são uma estrutura de dados mais versátil por pelo menos 3 motivos:
Os elementos podem ser de diferentes classes de objetos (p.ex.: um elemento
numeric, outrocharacter);Cada elemento pode ter um tamanho diferente;
Os elementos podem conter diferentes estrutura de dados (p.ex.: um elemento
matrix, outrovector);
Dentro da lista o conjunto de objetos são ordenados e cada elemento pode conter sub-elementos.
8.1.1 Criação
As vezes precisamos de um container para armazenar diferentes tipos de dados do R e com diferente tamanhos. As listas servem para isso e permitem armazenar qualquer número de itens de qualquer tipo. Uma lista pode conter números, caracteres ou uma mistura de dataframes, sub-listas, matrizes e vetores.
Listas podem ser criadas com a função list(). A especificação do conteúdo de uma lista é muito similar a da função c() vista anteriormente. Nós simplesmente listamos os dados que queremos como elementos da lista separados por vírgula dentro da função list().
# lista de dados heterogêneos
lst <- list(
# 4 vetores atômicos
c(1L, 6L, 10L, NA),
c(-1, 0, 1, 2, NA),
c(FALSE, NA, FALSE, TRUE),
c('ae', NA, "ou"),
# uma lista com 2 elementos
list(0, 1)
)
lst
#> [[1]]
#> [1] 1 6 10 NA
#>
#> [[2]]
#> [1] -1 0 1 2 NA
#>
#> [[3]]
#> [1] FALSE NA FALSE TRUE
#>
#> [[4]]
#> [1] "ae" NA "ou"
#>
#> [[5]]
#> [[5]][[1]]
#> [1] 0
#>
#> [[5]][[2]]
#> [1] 1Os índices em colchetes duplos [[]] identificam o elemento ou a componente da lista. Os índices em colchete simples [] indicam qual sub-elemento da lista está sendo mostrado. Por exemplo -1 é o primeiro elemento do vetor armazenado no segundo elemento da lista lst. Desse aninhamento de elementos surge o sistema de indexação de listas. A estrutura de uma lista pode se tornar complicada com o aumento do grau de sub-elementos. Mas essa flexibilidade, faz das listas uma ferramenta de armazenamento de dados para diversos propósitos.
Uma forma rápida de visualizar a estrutura de uma lista com a função str():
str(lst)
#> List of 5
#> $ : int [1:4] 1 6 10 NA
#> $ : num [1:5] -1 0 1 2 NA
#> $ : logi [1:4] FALSE NA FALSE TRUE
#> $ : chr [1:3] "ae" NA "ou"
#> $ :List of 2
#> ..$ : num 0
#> ..$ : num 1A saída mostra que a lista tem 5 elementos, para cada elemento é indicado seu tipo de dado. Uma lista pode armazenar uma lista dentro de suas componentes. Neste caso a lista é dita ser uma lista aninhada. Em algumas circunstâncias você pode precisar verificar se uma lista é aninhada e para isso usamos a função is.recursive().
is.recursive(lst)
#> [1] TRUEListas, por serem vetores, podem ter nomes:
names(lst)
#> NULL
names(lst) <- c("vetor_int", "vetor_dbl", "vetor_log", "vetor_char", "lista")Note a diferença de como é mostrada no console a lista após ter sido nomeado seus componentes:
lst
#> $vetor_int
#> [1] 1 6 10 NA
#>
#> $vetor_dbl
#> [1] -1 0 1 2 NA
#>
#> $vetor_log
#> [1] FALSE NA FALSE TRUE
#>
#> $vetor_char
#> [1] "ae" NA "ou"
#>
#> $lista
#> $lista[[1]]
#> [1] 0
#>
#> $lista[[2]]
#> [1] 1Ao invés do duplo colchetes, agora aparecem os nomes das componentes da lista precedidas do símbolo $. A lista interna da lst (5° elemento) segue sendo impressa com duplo colchetes uma vez que seus elementos não tem nomes.
Veremos que listas são frequentemente usadas para armazenar a saída de funções com diversos resultados. Como por exemplo a saída das funções rle(). Esta função é bastante útil para identificar sequência de dados repetidos.
8.1.2 Exemplo de lista com dados de estações meteorológicas
Vamos ver um exemplo onde criamos uma lista com dados e informações (metadados) de duas estações meteorológicas.
# matriz de dados meteorológicos da estação de Santa Maria
dados_sm <- cbind(
tar = c(31, 35, 21, 23, 33, 17),
prec = c(300, 200, 150, 120, 210, 110)
)
dados_sm
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110
# lista com informações da estação de santa maria
sm_l <- list(
c(-45, -23),
"Santa Maria",
dados_sm
)
sm_l
#> [[1]]
#> [1] -45 -23
#>
#> [[2]]
#> [1] "Santa Maria"
#>
#> [[3]]
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110
# adicionar nomes aos elementos
names(sm_l) <- c("coords", "cidade", "dados")
sm_l
#> $coords
#> [1] -45 -23
#>
#> $cidade
#> [1] "Santa Maria"
#>
#> $dados
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110
# matriz de dados meteorológicos da estação de Júlio de Castilhos
dados_jc <- cbind(
tar = c(22.5, 20, 18.75, 18, 20.25, 17.75),
prec = c(360, 310, 285, 270, 315, 265)
)
# criando lista de JC, mas nomeando de forma diferente
jc_l <- list(
coords = c(-45.1, -23.2),
cidade = "Júlio de Castilhos",
dados = dados_jc
)
# adicionar nomes as componentes
names(jc_l) <- names(sm_l)
jc_l
#> $coords
#> [1] -45.1 -23.2
#>
#> $cidade
#> [1] "Júlio de Castilhos"
#>
#> $dados
#> tar prec
#> [1,] 22.50 360
#> [2,] 20.00 310
#> [3,] 18.75 285
#> [4,] 18.00 270
#> [5,] 20.25 315
#> [6,] 17.75 265As informações de cada estação estão armazenadas em 2 listas. Mas é mais prático termos todas estações em um única lista:
# combinando listas mantendo os elementos separadamente
dados_l <- list(sm_l, jc_l)
dados_l
#> [[1]]
#> [[1]]$coords
#> [1] -45 -23
#>
#> [[1]]$cidade
#> [1] "Santa Maria"
#>
#> [[1]]$dados
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110
#>
#>
#> [[2]]
#> [[2]]$coords
#> [1] -45.1 -23.2
#>
#> [[2]]$cidade
#> [1] "Júlio de Castilhos"
#>
#> [[2]]$dados
#> tar prec
#> [1,] 22.50 360
#> [2,] 20.00 310
#> [3,] 18.75 285
#> [4,] 18.00 270
#> [5,] 20.25 315
#> [6,] 17.75 265
names(dados_l)
#> NULL
# nomes para cada estação
names(dados_l) <- c("sm", "jc")
dados_l
#> $sm
#> $sm$coords
#> [1] -45 -23
#>
#> $sm$cidade
#> [1] "Santa Maria"
#>
#> $sm$dados
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110
#>
#>
#> $jc
#> $jc$coords
#> [1] -45.1 -23.2
#>
#> $jc$cidade
#> [1] "Júlio de Castilhos"
#>
#> $jc$dados
#> tar prec
#> [1,] 22.50 360
#> [2,] 20.00 310
#> [3,] 18.75 285
#> [4,] 18.00 270
#> [5,] 20.25 315
#> [6,] 17.75 265
# tamanho da lista ou número de elementos da lista
length(dados_l)
#> [1] 2Vamos ver como ficou a estrutura da lista dados_l:
str(dados_l)
#> List of 2
#> $ sm:List of 3
#> ..$ coords: num [1:2] -45 -23
#> ..$ cidade: chr "Santa Maria"
#> ..$ dados : num [1:6, 1:2] 31 35 21 23 33 17 300 200 150 120 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:2] "tar" "prec"
#> $ jc:List of 3
#> ..$ coords: num [1:2] -45.1 -23.2
#> ..$ cidade: chr "Júlio de Castilhos"
#> ..$ dados : num [1:6, 1:2] 22.5 20 18.8 18 20.2 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:2] "tar" "prec"As listas também poderiam ser combinadas com função concatena ou combina c().
dados_l2 <- c(sm_l, jc_l)
str(dados_l2)
#> List of 6
#> $ coords: num [1:2] -45 -23
#> $ cidade: chr "Santa Maria"
#> $ dados : num [1:6, 1:2] 31 35 21 23 33 17 300 200 150 120 ...
#> ..- attr(*, "dimnames")=List of 2
#> .. ..$ : NULL
#> .. ..$ : chr [1:2] "tar" "prec"
#> $ coords: num [1:2] -45.1 -23.2
#> $ cidade: chr "Júlio de Castilhos"
#> $ dados : num [1:6, 1:2] 22.5 20 18.8 18 20.2 ...
#> ..- attr(*, "dimnames")=List of 2
#> .. ..$ : NULL
#> .. ..$ : chr [1:2] "tar" "prec"Perceba a diferença entre a lista combinada com list() (dados_l) e com c() (dados_l2). Esta última possui 6 elementos e com nomes repetidos, o que pode gerar confusão quando for selecionar os dados.
8.1.3 Indexação
8.1.3.1 Operador [
Assim como na indexação de vetores atômicos (7.5), podemos acessar os elementos de uma lista usando os colchetes [ com índices numéricos positivos, negativos, caracteres (nomes dos elementos) e lógicos. As expressões abaixo, ilustram o uso dessas diferentes formas de seleção de elementos e produzem o mesmo resultado.
# seleção dos dois primeiros elelemntos da lista
# por números
sm_l[1:2]
#> $coords
#> [1] -45 -23
#>
#> $cidade
#> [1] "Santa Maria"
# por nomes
sm_l[c("coords", "alt")]
#> $coords
#> [1] -45 -23
#>
#> $<NA>
#> NULLO resultado da seleção do 1º e 2º elemento é uma lista menor que a original. Isso não é muito útil, uma vez que muitas funções do R não lidam com listas. Por exemplo, se quiséssemos calcular a soma do vetor contido do primeiro elemento da lista lst obtém-se um erro.
# seleção do 1º elemento da lst
lst[1]
#> $vetor_int
#> [1] 1 6 10 NA
# o resultado da seleção é uma lista
mode(lst[1])
#> [1] "list"
# a função sum() espera como entrada um vetor
sum(lst[1])
#> Error in sum(lst[1]): invalid 'type' (list) of argument
# acessando elemento inexistente
lst[6]
#> $<NA>
#> NULLEntão ao selecionar elementos de uma lista com o operador [ o resultado preserva a estrutura original do objeto. lst é uma lista e o resultado da seleção lst[1] também é uma lista.
Portanto, a seleção de elementos com o operador [ preserva a estrutura de dados original.
8.1.3.2 Operador [[ e $
Na maioria das vezes estamos interessados no conteúdo dos elementos de uma lista. Para fazer isso há dois operadores:
duplo colchetes
[[sifrão
$
Para acessar elementos individuais de uma lista usamos o duplo colchetes [[ especificando o número do elemento ou o nome. Essa forma de seleção de dados permite o acesso a um elemento por vez.
# 1º elemento de sm_l
sm_l[[1]]
#> [1] -45 -23
sm_l[["coords"]]
#> [1] -45 -23
# ultimo elemento de sm_l
sm_l[[length(sm_l)]]
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110
sm_l[["dados"]]
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110A indexação pode ser combinada, por exemplo: para extrair da estação sm (1° elemento da dados_l) o nome da cidade (2° sub-elemento), fazemos:
dados_l[["sm"]][["cidade"]]
#> [1] "Santa Maria"Para acessar o conteúdo de elementos de uma lista que possui nomes podemos também usar o operador $. Ele funciona de forma similar ao duplo colchetes usado com o nome do elemento da lista. Mas esse operador tem duas vantagens: a IDE RStudio autocompleta o nome do elemento (usando a tecla <tab>) e o ![]() aceita o nome parcial dos nomes dos elementos.
aceita o nome parcial dos nomes dos elementos.
# seleção de dados por nomes usando o símbolo $
dados_l$s
#> $coords
#> [1] -45 -23
#>
#> $cidade
#> [1] "Santa Maria"
#>
#> $dados
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110
dados_l$j
#> $coords
#> [1] -45.1 -23.2
#>
#> $cidade
#> [1] "Júlio de Castilhos"
#>
#> $dados
#> tar prec
#> [1,] 22.50 360
#> [2,] 20.00 310
#> [3,] 18.75 285
#> [4,] 18.00 270
#> [5,] 20.25 315
#> [6,] 17.75 265Com o operador $, para extrair da estação sm (1° elemento da dados_l) o nome da cidade (2° sub-elemento), fazemos:
dados_l$sm$cidade
#> [1] "Santa Maria"8.1.3.3 Lista de condimentos
É fácil de confundir quando usar ] e ]]. A tabela abaixo ajuda lembrar da diferença entre eles.
| descrição | código | resultado |
|---|---|---|
| frasco de pimenta | frasco | 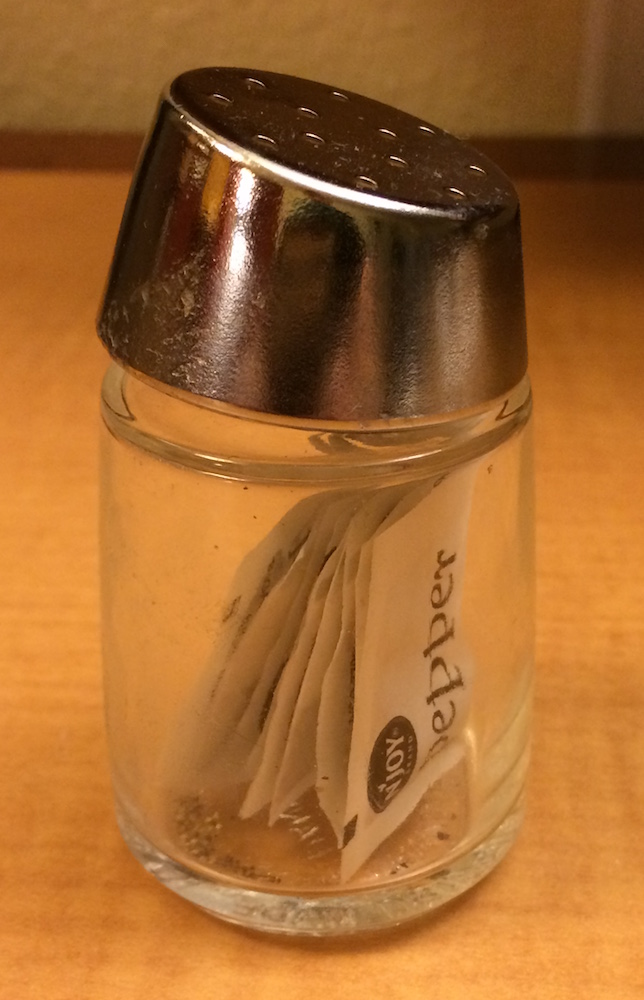 |
| frasco de pimenta com apenas 1 pacote de pimenta | frasco[1] | 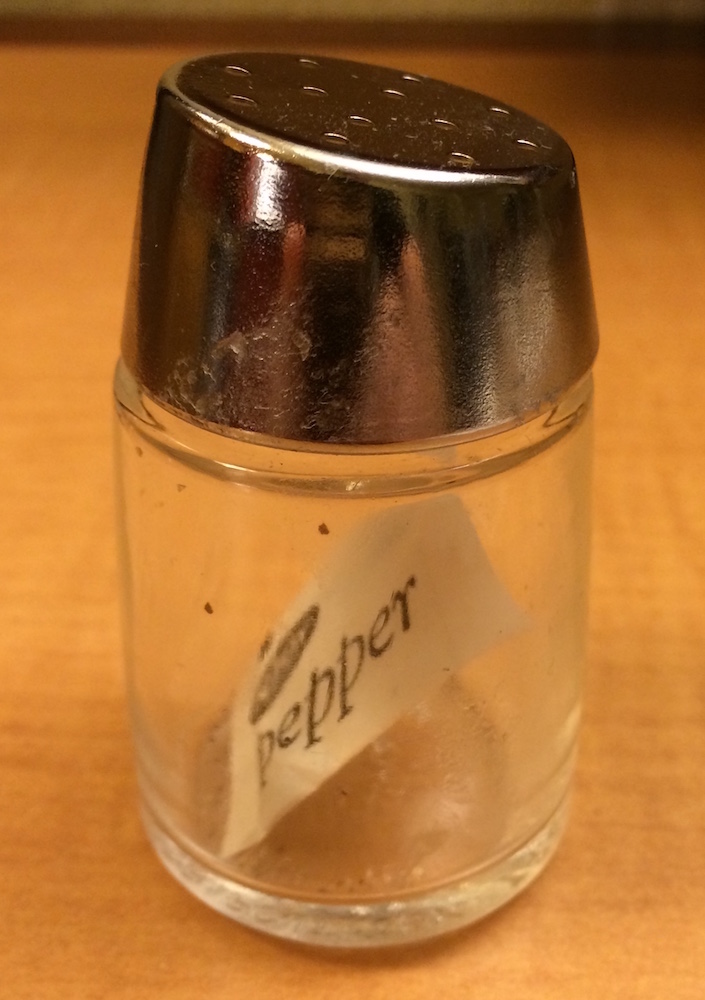 |
| 1 pacote de pimenta | frasco[[1]] |  |
| conteúdo de um pacote de pimenta | frasco[[1]][[1]] |  |
8.1.4 Conversão de lista para vetor e vice-versa.
Um vetor é convertido para listacom a função as.list().
va <- 1:10
va
#> [1] 1 2 3 4 5 6 7 8 9 10
va_list <- as.list(va)
va_list
#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3
#>
#> [[4]]
#> [1] 4
#>
#> [[5]]
#> [1] 5
#>
#> [[6]]
#> [1] 6
#>
#> [[7]]
#> [1] 7
#>
#> [[8]]
#> [1] 8
#>
#> [[9]]
#> [1] 9
#>
#> [[10]]
#> [1] 10Você pode "desmanchar" uma lista com a função unlist():
# desmanchando a lista
unlist(va_list)
#> [1] 1 2 3 4 5 6 7 8 9 10Ou seja a lista é convertida em vetor atômico.
A remoção de um elemento da lista pode ser feita usando a indexação e o valor NULL.
str(va_list)
#> List of 10
#> $ : int 1
#> $ : int 2
#> $ : int 3
#> $ : int 4
#> $ : int 5
#> $ : int 6
#> $ : int 7
#> $ : int 8
#> $ : int 9
#> $ : int 10
va_list[8] <- NULL
str(va_list)
#> List of 9
#> $ : int 1
#> $ : int 2
#> $ : int 3
#> $ : int 4
#> $ : int 5
#> $ : int 6
#> $ : int 7
#> $ : int 9
#> $ : int 108.1.5 Conversão de list para data.frame
Vamos modificar a lista sm_l para convertê-la em um dataframe.
sm_l
#> $coords
#> [1] -45 -23
#>
#> $cidade
#> [1] "Santa Maria"
#>
#> $dados
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110
# ao invés da componente coords, criamos uma lon e lat
sm_l$lon <- sm_l$coords[1]
sm_l$lat <- sm_l$coords[2]
sm_l$coords <- NULL
sm_l
#> $cidade
#> [1] "Santa Maria"
#>
#> $dados
#> tar prec
#> [1,] 31 300
#> [2,] 35 200
#> [3,] 21 150
#> [4,] 23 120
#> [5,] 33 210
#> [6,] 17 110
#>
#> $lon
#> [1] -45
#>
#> $lat
#> [1] -23
# converter para dataframe
sm_df <- data.frame(sm_l)
sm_df
#> cidade dados.tar dados.prec lon lat
#> 1 Santa Maria 31 300 -45 -23
#> 2 Santa Maria 35 200 -45 -23
#> 3 Santa Maria 21 150 -45 -23
#> 4 Santa Maria 23 120 -45 -23
#> 5 Santa Maria 33 210 -45 -23
#> 6 Santa Maria 17 110 -45 -23