Capítulo 10 Processamento de dados
Neste capítulo veremos:
um quadro de dados aperfeiçoado, denominado tibble
como arrumar seus dados em uma estrutura conveniente para a análise e visualização de dados
como reestruturar os dados de uma forma versátil e fácil de entender
como manipular os dados com uma ferramenta intuitiva e padronizada
Existem diversas ferramentas da base do ![]() para realizar as operações listadas acima. Entretanto, elas não foram construídas para um objetivo comum e foram feitas por diferentes desenvolvedores e em diferentes fases da evolução do
para realizar as operações listadas acima. Entretanto, elas não foram construídas para um objetivo comum e foram feitas por diferentes desenvolvedores e em diferentes fases da evolução do ![]() . Por isso, elas podem parecer confusas, não seguem uma codificação consistente e não foram construídas pensando em uma interface integrada para o processamento de dados. Conseqüentemente, para usá-las é necessários um esforço significativo para entender a estrutura de dados de entrada de cada uma. A seguir, precisamos padronizar suas saídas para que sirvam de entrada para outra função (às vezes de outro pacote) que facilita a realização de uma próxima etapa do fluxo de trabalho.
. Por isso, elas podem parecer confusas, não seguem uma codificação consistente e não foram construídas pensando em uma interface integrada para o processamento de dados. Conseqüentemente, para usá-las é necessários um esforço significativo para entender a estrutura de dados de entrada de cada uma. A seguir, precisamos padronizar suas saídas para que sirvam de entrada para outra função (às vezes de outro pacote) que facilita a realização de uma próxima etapa do fluxo de trabalho.
Muitas coisas no ![]() que foram desenvolvidas há 20 anos atrás são úteis até hoje. Mas as mesmas ferramentas podem não ser a melhor solução para os problemas contemporâneos. Alterar os códigos da base do
que foram desenvolvidas há 20 anos atrás são úteis até hoje. Mas as mesmas ferramentas podem não ser a melhor solução para os problemas contemporâneos. Alterar os códigos da base do ![]() é uma tarefa complicada devido a cadeia de dependências do código fonte e dos pacotes dos milhares de contribuidores. Então, grande parte das inovações no
é uma tarefa complicada devido a cadeia de dependências do código fonte e dos pacotes dos milhares de contribuidores. Então, grande parte das inovações no ![]() estão ocorrendo na forma de pacotes. Um exemplo é o conjunto de pacotes tidyverse desenvolvido para suprir a necessidade de ferramentas efetivas e integradas para ciência de dados (Figura 10.1).
estão ocorrendo na forma de pacotes. Um exemplo é o conjunto de pacotes tidyverse desenvolvido para suprir a necessidade de ferramentas efetivas e integradas para ciência de dados (Figura 10.1).
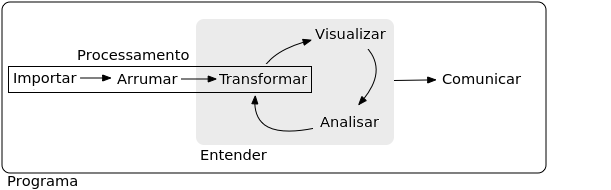
Figura 10.1: Modelo de ferramentas empregadas em ciência de dados. Adaptado de H. Wickham and Grolemund (2017).
O termo tidyverse pode ser traduzido como 'universo arrumado' e consiste em uma coleção de pacotes (Figura 10.2) que compartilham uma interface comum com padrões de estrutura e manipulação de dados (H. Wickham et al. 2017, H. Wickham (2014)).
O tidyverse tem sido amplamente utilizado pela comunidade de usuários e desenvolvedores do ![]() . Além de uma abordagem mais coesa e consistente para realizar as tarefas envolvidas no processamento de dados, os códigos são mais eficientes, legíveis e com sintaxe mais fácil de lembrar. Consequentemente, focamos mais nos conceitos e menos na sintaxe.
. Além de uma abordagem mais coesa e consistente para realizar as tarefas envolvidas no processamento de dados, os códigos são mais eficientes, legíveis e com sintaxe mais fácil de lembrar. Consequentemente, focamos mais nos conceitos e menos na sintaxe.
Figura 10.2: Coleção de pacotes do tidyverse.
O tidyverse enfatiza legibilidade ao invés de desempenho. Para quem está começando a programar ele atenderá à maioria dos processos analíticos, mas pode não ser rápido o suficiente para um sistema de processamento de dados operacional de alta demanda. Se você precisa avançar nesta linha, você precisará se aprofundar em ferramentas específicas (veja por exemplo Gillespie and Lovelace (2017)).